こんにちは、NTです!
弊社毎年恒例となっているアドベントカレンダー終盤に差し掛かり、
ちゃんと技術ネタで2連チャンしようと思っております。
技術要素としては、音声から文字を起こしてくれるAIの中でも日本語に特化して
最近アップデートがあり、精度向上と高速化したと巷で有名な「kotoba-whisper」を用いて文字起こしした結果を前回紹介したAWSのLLMサービスであるBedrockでまとめるところまでしてみようと思います。
今回使用するAWSサービスは以下の通りです。
前編、後編と分けて公開しますのでどちらも閲覧いただけたらと思います。
前編:AWS Batchを用いてGPU EC2インスタンス上でkotoba-whisperを実行し音声の文字起こし
後編:前編で出力されたテキストをAWS Bedrockに読み取ってもらい、議事録を作成してもらう
※今回は検証で使えそうな会議音声がすぐに用意できなかったので、既に著作権が切れている夏目漱石の「坊ちゃん」の音声コーパス(約3時間30分)を使用しています。
今回は全てus-east-1(バージニア北部)AWSリージョン上で構築、実行しています。
詳細なコマンド等は省きますが、以下のDockerfileを用いてNVIDIAのCUDAコアが使用できる
コンテナをビルドし、AWS ECRのテスト用リポジトリにプッシュします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04 ENV TZ=Asia/Tokyo RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime RUN apt-get update && \ apt-get install -y \ python3-pip \ python3-dev \ ffmpeg \ git \ tzdata RUN pip install --upgrade pip RUN pip install transformers accelerate torchaudio boto3 stable-ts==2.16.0 punctuators==0.0.5 RUN pip install flash-attn --no-build-isolation WORKDIR /usr/src COPY ./src ./src CMD [ "python3", "src/main.py" ] |
Hugging Faceで公開されている「Kotoba-Whisper-v2.1」を使用しました。
※最新版のv2.2は別ライブラリの承認が必要だったので手短にv2.1にしました
実行方法なども書かれているので試したソースコードは共有しませんが、
ざっくり言うと以下の手順をmain.pyに記載して実行しています。
- 指定したS3パスから音声データをダウンロード
- ダウンロードした音声データをKotoba-Whisperに読み込ませて変数に出力
- 出力された物をローカル内でtxtファイルを生成
- txtファイルをS3の指定した場所へアップロード
以下のようにAWS Batchを構築しておくことで、いつでもつよつよマシンを自分の環境で実行することができるようになります。
※自身のAWSアカウントなのでID系の部分はマスキングしてあります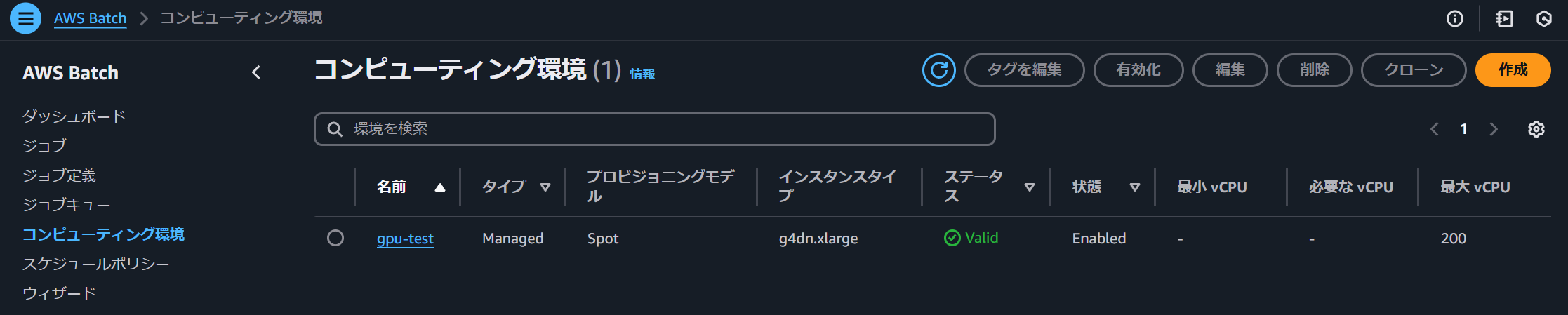
 現在、最大200vCPUまで同時実行可能にしてあるコンピューティング環境で、
現在、最大200vCPUまで同時実行可能にしてあるコンピューティング環境で、
1つ1つのジョブについては、4CPU 16GB でGPUはNVIDIA T4を用いた環境で実行していることが分かります。
この環境で3時間30分の音声を文字起こしすると、約300秒程度で完了していました。
出力された文字数は55,000文字となってました。
AWS Batch自体はEC2の起動からAIモデルのロードまで全て込み込みで6分10秒の実行で終了していました。
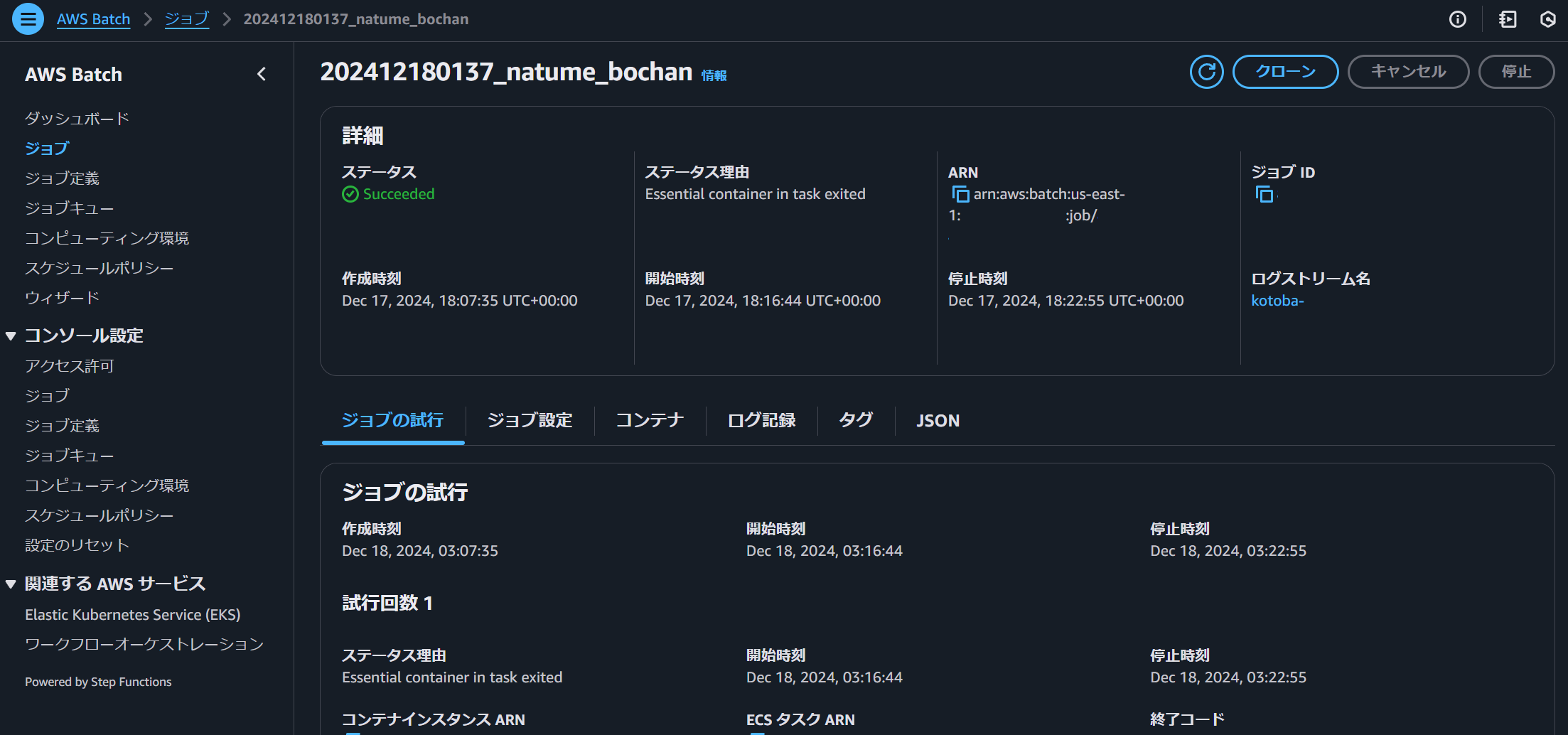
所感としては、処理速度が想像以上にかなり速いことと、精度もそこそこですが良い結果でした。
ただ、小説の音声コーパスを使用したので実際の会話ベースの音声であればもう少し精度が上がったかなと感じています。
今回実行したg4dn.xlargeというインスタンスですが、少し前のNVIDIAコアを搭載しているので、
高速化となる技術は無効化して実行しました。
これがg6.xlargeインスタンスなどのNVIDIA L4コアを使用すると更に高速化できそうなので、
もっと長時間な音声データを変換する際は効果的だと思います。
以上で、音声データの文字起こしは完了となります。
文字起こししたテキストを使用してどのようにまとめられるのか後編をお楽しみください!


